Can You Replace Your Software Engineers With AI?


The AI Engineer Debate
The simple answer is no; AI is not poised to replace software engineering teams in the foreseeable future. One reason lies in the benchmarks currently used to evaluate Large Language Models (LLMs) and autonomous agents, which do not fully capture the complexity of tasks that software engineers handle daily. Moreover, even against these somewhat simplified benchmarks, LLMs and the latest autonomous agents have shown subpar performance.
Additionally, being a software engineer isn’t just about coding. AI faces challenges in areas that require deep human insights and collaboration. It lacks the depth of critical thinking that humans apply when faced with complex, non-linear problems. It struggles to grasp the emotional resonance and contextual appropriateness that human designers consider. Moreover, accurately anticipating user needs requires a level of intuition and adaptability that AI has not yet mastered without human assistance.
Despite this, the development of LLMs and autonomous agents is advancing rapidly, becoming more affordable, efficient, and capable. This article aims to delve into the use of benchmarks for assessing the evolution of autonomous AI engineers.
The Promise of AI: Exploring Devin's Capabilities
Cognition Labs recently introduced Devin, an autonomous AI software engineer, in a blog post featuring videos that highlight its skills such as: developing and deploying apps, fixing bugs, handling open-source project issues, contributing to established software projects, and completing real tasks on Upwork.
The videos show Devin using a series of developer tools such as a shell, code editor, and browser within a sandboxed compute environment to accomplish these tasks. Cognition’s website also includes a link to a waiting list for those wishing to “hire” Devin.
The videos make Devin's tasks seem impressive, but in reality, they're quite straightforward, similar to what you'd find in introductory developer tutorials or coding interviews. For example, one video shows Devin fixing a common bug in a programming competition's algorithm repository, a typical example of problems included in LLM training datasets and evaluation benchmarks.
Comparing Devin's Tasks to Junior Developer Responsibilities
The tasks Devin performs, while appearing advanced, are actually more basic than the real-world challenges faced by junior developers on a software team. For instance:
- Developing User-Facing Features: Unlike Devin's demonstrations, junior developers often build complex features within applications. These tasks require collaboration with a team, adherence to a design system, and ensuring the application meets the needs of actual users.
- Solving Complex Backend Issues: Junior developers also tackle intricate problems in production environments, such as fixing bugs in systems with multiple databases and servers. This work is far more complicated than the tasks shown by Devin, involving deeper analysis and problem-solving skills.
Benchmarks and Reality: Assessing AI's Software Engineering Skills
The thing that did impress me about Devin was the following claim:
“We evaluated Devin on SWE-bench, a challenging benchmark that asks agents to resolve real-world GitHub issues found in open source projects like Django and scikit-learn.
Devin correctly resolves 13.86%* of the issues end-to-end, far exceeding the previous state-of-the-art of 1.96%. Even when given the exact files to edit, the best previous models can only resolve 4.80% of issues.”
To appreciate this achievement, it's crucial to see how LLMs are tested on coding challenges. One prominent example is HumanEval by OpenAI, which tests basic programming skills through 164 Python problems, each with a function to write and tests to pass, like summing uppercase characters in a string. While intriguing, these tasks are far simpler than daily software engineering work, often resembling interview questions more than real-world problems.
Unpacking SWE-bench: Why It's a Better Benchmark for AI in Software Engineering
In contrast, SWE-bench offers a more realistic gauge of LLMs' capabilities. It comprises 2,294 tasks drawn from actual GitHub issues and pull requests, requiring LLMs to navigate and modify codebases to solve real problems. This benchmark demands a deeper level of understanding and interaction with the code, reflecting the complexity of software engineering more accurately than simpler benchmarks like HumanEval.
Let's explore the SWE-bench paper for a closer look at the Python repositories involved, their data sources, and how it measures performance. The paper includes a pie chart showing the distribution of problems and their origins:
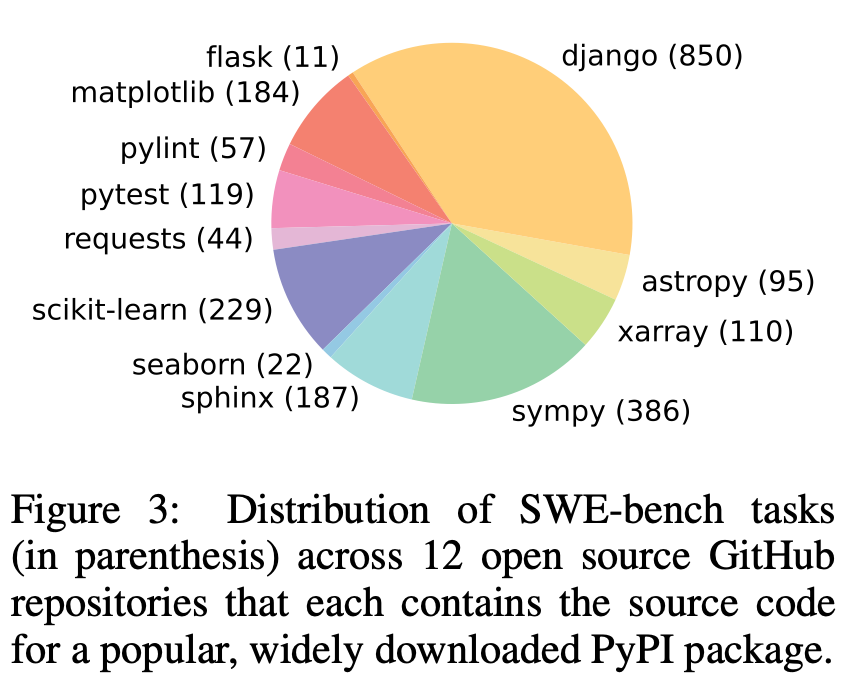
If you're into Python development, you likely know some of these libraries. Now, let's see what criteria it used to select and scrape these problems:

In SWE-bench tests, an AI is tasked with solving a described problem within a provided codebase. The AI's edits are submitted as patch files that specify the necessary code modifications. The AI's solution is deemed successful if, after applying the patch, the associated code tests pass. The benchmark's effectiveness is gauged by the number of problems the AI manages to solve.
While this is better than HumanEval it’s still less than ideal as a benchmark. Real-life software engineering involves complex systems and technologies, such as Kubernetes, Docker, and cloud services like AWS, which are challenging to replicate in simple benchmarks. This illustrates the gap between typical LLM testing scenarios and the nuanced, multifaceted tasks engineers face.
Unpacking SWE-bench: Inspecting Test Data
The SWE-Bench training data is accessible on Huggingface, stored in a '.parquet' file format, which isn't as straightforward to examine as the HumanEval data. I've created a Python script using the pandas library to load and display this data, allowing you to review the problems it includes, such as one of the 850 Django-related issues. Here is one of the problems as an example:
“Title: Add an option to django-admin to always colorize output
Description: With Django management commands, it is currently possible disable colors with the --no-colors flag.
What I'd like to have is basically the other side of the coin: a --force-colors flag that instructs Django to output ANSI color sequences in cases it would disable colors by default (typically, when the output is piped to another command, as documented).
My real world use-case is the following one: I have a custom Django command to import data. I run this command myself, and I'd like to send a colored log (HTML seems perfect for this) to the data curators. I can use the https://github.com/theZiz/aha utility for this, but that doesn't work since Django disable colors when the output is piped.
Other *nix commands have a special flag for this exact use-case, for example $ ls --color=always
Created At: 2018-07-22 17:15:08
Patch Size: 71 lines”
The original issue and its pull request with tests are available here. Despite being six years old, it mirrors real software engineering tasks I have encountered.
SWE-Bench addresses the challenge of a large codebase that might be too extensive for a Language Model (LLM) to handle in one go by using two key techniques:
- Sparse Retrieval: It selects relevant files within a set limit for the AI to review, which helps when dealing with complex code.
- Oracle Retrieval: This approach uses files known to resolve an issue, although it's less realistic because engineers don't usually know which files will need edits in advance.
Sparse retrieval is practical, but "oracle" retrieval seems unfair as it hints to LLMs which files were changed. Performance-wise, models like Claude 2 only resolved around 4.8% of issues with "oracle" hints and just 1.96% without.
This is why in contrast, Devin's claimed success rate of 13.8% without specific guidance stands out to me as really impressive.
Conclusion: AI and Human Engineers – Collaborators, Not Competitors
Numerous product features, updates and vital bug fixes go unshipped due to a shortfall in engineering capacity. I’ve seen this happen repeatedly in quarterly planning at larger companies. Additionally, our ability to predict future tech needs is frequently overestimated. As routine tasks become automated by AI, engineers will shift focus to more complex and creative challenges, thereby generating new opportunities for innovation.
In 2024, the tech job market is struggling, leading to widespread job security concerns. However, I believe AI is not the cause of these issues. On the contrary, without the current growth in AI, the situation could be even grimmer. AI's boom is driving investment and hiring in startups, preventing a potentially worse job market downturn.
However, this evolving landscape presents an opportunity. By developing better benchmarks and training data that mirror the nuanced activities of software engineers, AI can be groomed to automate the mundane, freeing us to focus on more creative and high-value endeavors.
At my AI startup, StepChange, we're developing an open-source project focused on enhancing training data by collaborating with experts to automate mundane data infrastructure tasks such as upgrades and migrations.
If the idea of AI enhancing rather than replacing human roles in software development inspires you, I invite you to collaborate with us. We're on a mission to use AI to streamline routine tasks, freeing us to apply our creativity and problem-solving to areas where the human touch is indispensable. If you're interested in developing better benchmarks or automating tedious software tasks, reach out to me at harry (at) stepchange.work. Let's innovate together and shape the future of software development.